By
By
What is a Part of Speech?
Part of Speech (POS) is a way to describe the grammatical function of a word. In Natural Language Processing (NLP), POS is an essential building block of language models and interpreting text. While POS tags are used in higher-level functions of NLP, it's important to understand them on their own, and it's possible to leverage them for useful purposes in your text analysis.
There is a hierarchy of tasks in NLP (see Natural language processing for a list). At the bottom are sentence and word segmentation. POS tagging builds on top of that, and phrase chunking builds on top of POS tags. These tags, in turn, can be used as features for higher-level tasks such as building parse trees, which can, in turn, be used for Named Entity Resolution, Coreference Resolution, Sentiment Analysis, and Question Answering.
There are eight (sometimes nine) different parts of speech in English that are commonly defined 3.
- Noun: A noun is the name of a person, place, thing, or idea.
- Pronoun: A pronoun is a word used in place of a noun.
- Verb: A verb expresses action or being.
- Adjective: An adjective modifies or describes a noun or pronoun.
- Adverb: An adverb modifies or describes a verb, an adjective, or another adverb.
- Preposition: A preposition is a word placed before a noun or pronoun to form a phrase modifying another word in the sentence.
- Conjunction: A conjunction joins words, phrases, or clauses.
- Interjection: An interjection is a word used to express emotion.
- Determiner or Article: A grammatical marker of definiteness (the) or indefiniteness (a, an). These are not always considered POS but are often included in POS tagging libraries.
The Basics of POS Tagging
Let's start with some simple examples of POS tagging with three common Python libraries: NLTK, TextBlob, and Spacy. We'll do the absolute basics for each and compare the results.
Start by importing all the needed libraries.
import nltk
from textblob import TextBlob
from textblob.taggers import PatternTagger
import spacy
For our examples, we'll use two sentences with a common word, book, which can be a noun or a verb, to test how well the POS taggers work in context.
- Please book my flight to California
- I read a very good book
NLTK
Let's start with the most common library for NLP in Python; the Natural Language Toolkit or NLTK.
tokenized_sent = nltk.sent_tokenize("Please book my flight to California")
[nltk.pos_tag(nltk.word_tokenize(word)) for word in tokenized_sent]
[[('Please', 'NNP'),
('book', 'NN'),
('my', 'PRP$'),
('flight', 'NN'),
('to', 'TO'),
('California', 'NNP')]]
tokenized_sent = nltk.sent_tokenize("I read a very good book")
[nltk.pos_tag(nltk.word_tokenize(word)) for word in tokenized_sent]
[[('I', 'PRP'),
('read', 'VBP'),
('a', 'DT'),
('very', 'RB'),
('good', 'JJ'),
('book', 'NN')]]
What we notice here is that for the most part, NLTK properly recognizes the word in context; however, a few errors such as Please is tagged as a Proper Noun (NNP) and bookis tagged as a Noun (NN) in our first sentence when it should be a Verb (VB).
Note: For a list of what the tags mean, see Penn Treebank Project.
TextBlob
Let's try another library called TextBlob which provides a simple API for diving into standard natural language processing (NLP) tasks 5. It's a very good Pythonic implementation of an NLP library and simplifies some of the common NLP tasks. Much of what TextBlob does is wrap NLTK and other popular NLP libraries to make them easier to use.
blob = TextBlob("Please book my flight to California", pos_tagger=PatternTagger())
blob.tags
[('Please', 'VB'),
('book', 'NN'),
('my', 'PRP$'),
('flight', 'NN'),
('to', 'TO'),
('California', 'NNP')]
blob = TextBlob("I read a very good book", pos_tagger=PatternTagger())
blob.tags
[('I', 'PRP'),
('read', 'VB'),
('a', 'DT'),
('very', 'RB'),
('good', 'JJ'),
('book', 'NN')]
Notice the use of PatternTagger in the initialization of the Blob. The default is to use NLTK's tagger, yielding the same results as above. This allows us to try a different POS Tagger and check its performance. We can see that TextBlob correctly identifies Please as a Verb this time but still misses Book as a Verb in the first sentence.
Spacy
Spacy is the most modern and advanced of the three of these. It's incredibly robust for tons of NLP tasks and allows for customization if more power is needed. This is currently my favorite NLP library, and let's check it out with our sentences.
doc = nlp("Please book my flight to California")
for token in doc:
print(token.text, token.pos_)
Please INTJ
book VERB
my PRON
flight NOUN
to ADP
California PROPN
doc = nlp("I read a very good book")
for token in doc:
print(token.text, token.pos_)
I PRON
read VERB
a DET
very ADV
good ADJ
book NOUN
We see here that Spacy correctly tagged all of our words, and it identified Please like an Interjection as opposed to a Verb, which is more accurate and also identified Book as a Verb in the first sentence.
Each of these libraries has its pros and cons. I believe you should start with NLTK to understand how it works, especially since it has so much robust support of different corpora. TextBlob is great when you want simplicity across several NLP tasks, and Spacywhen you want one of the most robust NLP libraries around.
Check out this great Series NLTK with Python for Natural Language from PythonProgramming.net.
Voice of Customer Analysis with Parts of Speech
One of the most common tasks performed with NLP is analyzing customer feedback from various sources and determining what customers are talking about for your product or service. This type of analysis is called Voice of Customer Analysis or VOC.
There are many ways to perform a VOC analysis. From Sentiment Analysis to Topic Modeling, one method you can use is Part of Speech tagging to narrow what customers are talking about and how they talk about your products and services.
Text for your analysis can come from survey responses, support tickets, Facebook comments, Tweets, chat conversations, emails, call transcripts, and online reviews. Let's say you have a collection of customer reviews. One of the things you might want to identify is all the products that people are talking about. You may have a perfect categorization of your products in a database, but what if you don't at the granular level you need? For this example, we will use the dataset of Women's E-Commerce Clothing Reviews on Kaggle.
After importing the dataset, we can create a new DataFrame of all the words and their POS tag. The function below takes each review and determines the POS tag for each word; an important distinction because we get the context of each word in the sentence, and as we saw above, this makes a big difference in which POS tag is associated.
def pos_tag(text):
df = pd.DataFrame(columns = ['WORD', 'POS'])
doc = nlp(text)
for token in doc:
df = df.append({'WORD': token.text, 'POS': token.pos_}, ignore_index=True)
return df
Next, we can run the function on a subset of the reviews. Since we're using individual words, the quantity can be in the millions, and we most likely don't need the entire dataset.
# Take a random sample of reviews
df2 = df.sample(10000, random_state=42).copy()
# Create an empty dataframe to store the results
df_pos = pd.DataFrame(columns = ['WORD', 'POS'])
# Iterate through the reviews and append each POS tag to the dataframe
df_pos = pos_tag(df2['Review Text'].to_string())
df_pos.shape
(144498, 2)
Next, we can group and count each of the POS tags to see the most frequent ones.
df_top_pos = df_pos.groupby('POS')['POS'].count().\
reset_index(name='count').sort_values(['count'],ascending=False).head(15)
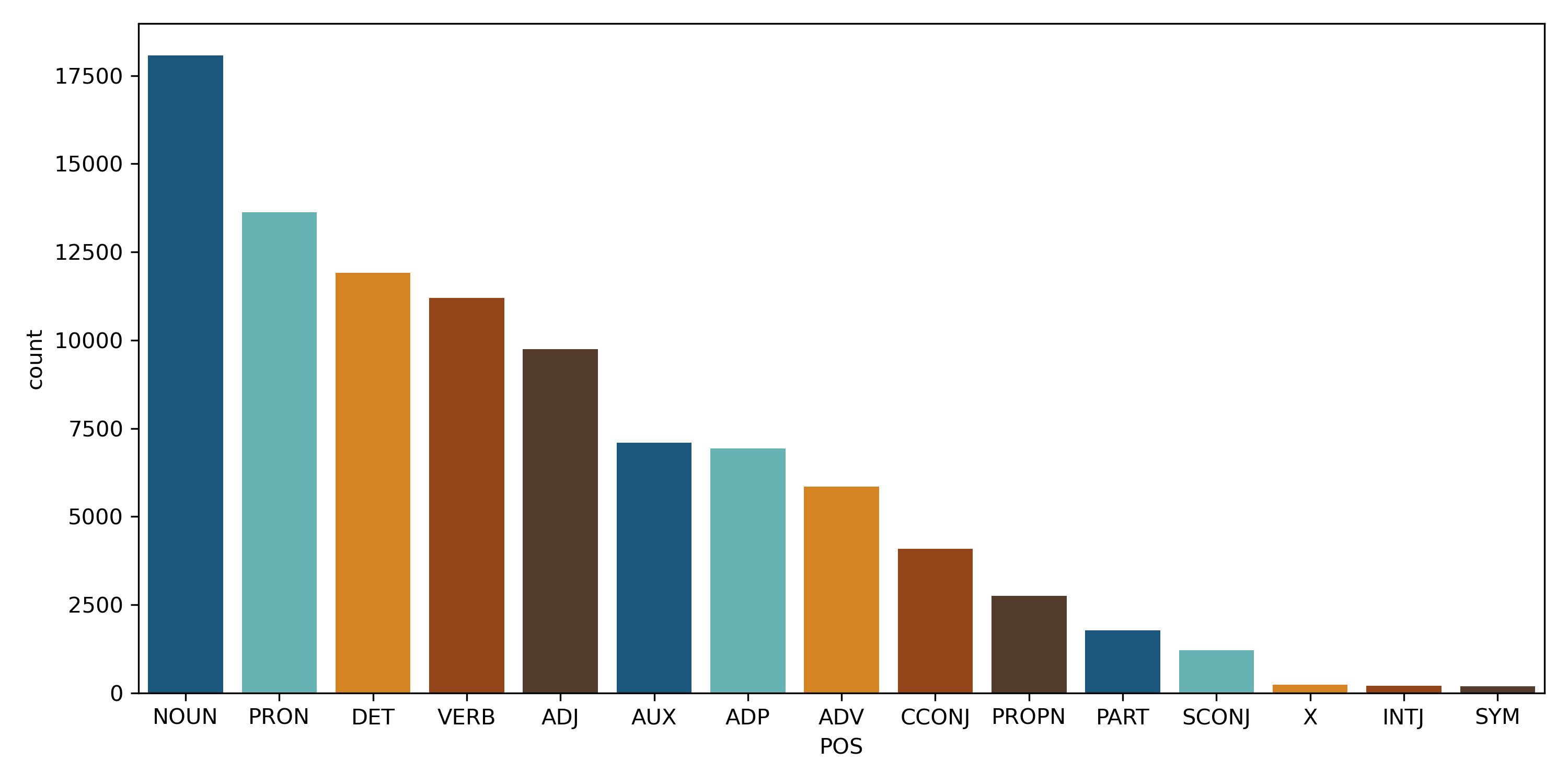
Great! We have lots of tags and words. However, these don't quite tell us much on their own, giving us a view of the distribution of different tags. However, now we can use our tags to pull out words that might represent products vs. those that represent other words in our reviews. For this, we can filter for just the Nouns.
df_nn = df_pos[df_pos['POS'] == 'NOUN'].copy()
df_nn.groupby('WORD')['WORD'].count().reset_index(name='count').\
sort_values(['count'], ascending=False).head(10)
WORD count
667 dress 1779
2062 top 1176
1764 shirt 463
1971 sweater 437
453 color 383
1807 size 312
765 fabric 287
1922 store 274
1822 skirt 256
1416 pants 246
Look at that! We have the top 15 words used in this subset of reviews and most of them look like product categories. What if we now look at the top Adjectives for the same subset of reviews?
df_adj = df_pos[df_pos['POS'] == 'ADJ'].copy()
df_adj.groupby('WORD')['WORD'].count().reset_index(name='count').\
sort_values(['count'], ascending=False).head(15)
WORD count
400 great 481
144 beautiful 405
248 cute 398
784 soft 321
218 comfortable 272
632 perfect 243
585 nice 196
776 small 176
41 Great 149
666 pretty 146
394 gorgeous 144
511 little 142
611 other 142
523 lovely 125
349 flattering 122
Tada 🎉! the top-most used words that describes how our customers are talking about our products. We have lost some positive words but also some that might be worth looking into. Things such as small and little speak potentially to a sizing issue where some clothes are not true to fit. A product manager can take this information and dive deeper into the reviews that mention this word.
As mentioned, there are other ways to analyze text that might be better, such as Sentiment Analysis and Topic Modeling. However, this is a fun way to apply POS tagging in a practical use case and even be combined with those other NLP tools to help you get the most out of your customer's feedback.
All the code for this analysis is available on GitHub