By
By
ELT (Extract-Load-Transform)
Traditionally, you loaded data into a data warehouse through a process called Extract, Transform, and Load or ETL. In the ETL process, you would extract data from a source system, transform it with external computing such as Apache Spark, and then load it into the Warehouse in its final format.
With the rise of modern Data Warehouses, we invert the second and third parts of the process to perform Extract, Load, and Transform, known as ELT. In ELT, we extract data from a source system, load it into the Warehouse, and then transform it. This process allows us to perform transformations in the Warehouse, which can also be much fasterthan in a separate computing engine. You also can reduce the complexity of your data pipeline by removing the need for an external computing engine.
The Challenge
How do you do this transformation? One way that you might turn to at first is to write SQL scripts that create SQL Views in your Warehouse that perform these transformations and present your data how you like. This method is technically the right thing to do. However, the catch is that as you scale the number of views you create, there is a very high risk of having issues managing the code needed to create all these transformations. Good luck keeping track of multiple people's code if you work on a team. It can become a nightmare quickly!
Let's introduce dbt!
Note: If you'd like a detailed look into the above process (minus dbt), you can check out this article: Getting Started with Snowflake and the Rise of ELT Workflows in the Cloud
Introduction to dbt: The "T" in ELT Workflows
dbt is an incredibly popular tool in the data community today. If you search the internet for terms like Modern Data Stack in almost every image or article, you'll see a reference to dbt. It's everywhere; if you're a data practitioner, you must learn it.
dbt stands for Data Build Tool, and according to their website, they describe it as:
dbt™ is a SQL-first transformation workflow that lets teams quickly and collaboratively deploy analytics code following software engineering best practices like modularity, portability, CI/CD, and documentation. Now, anyone on the data team can safely contribute to production-grade data pipelines.
In simpler terms, that means you can take the View creation scripts you were manually creating, and you can manage them as source code and automate their deployment to your Warehouse.
dbt is available in a couple of different flavors. First, you can get the open-source dbt Core with an Apache 2.0 license. dbt Core can be useful if you're integrating dbt into another workflow. You will find dbt Core is integrated into other tools, such as Fivetran, a powerful tool for loading data into your Warehouse. The second and my preferred way is to create a dbt Cloud account and utilize this as your IDE and the engine to run your dbt workflows. dbt offers an excellent free tier that allows you to get started, learn dbt, or even run a small business.
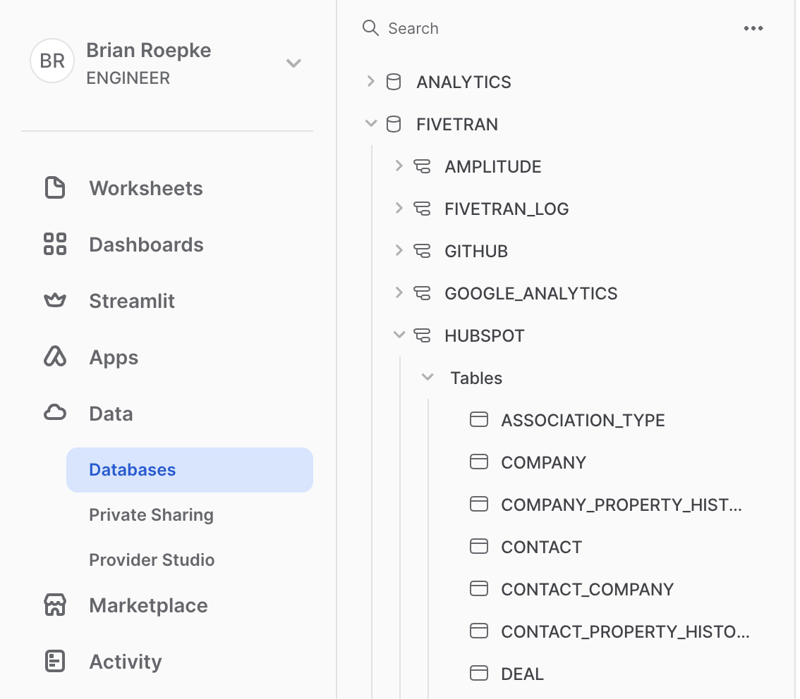
Data Warehouse Ingestion DB
One common method is to have a dedicated database in your Warehouse where the Extract and Load process happens. You might have more than one, but generally, you ingest data into this location and never operate off that directly. This data can be controlled by an external service or process that regularly updates the data from your source systems. In this example, I'm using Fivetran to load the data from common SaaS tools like Amplitude, Google Analytics, GitHub, and HubSpot.
Models
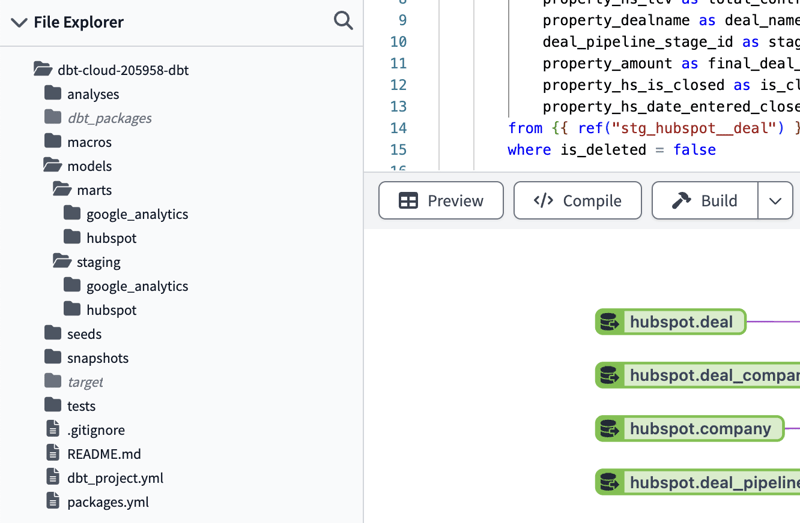
The first conceptin dbt that you need to know is Models. Models represent an SQL file that is the code to create a View or a building block of one. A best practice is to break down models into smaller parts to make the code more modular, scalable, and readable. The most common practice taught by dbt is to break down the original code into three different types of models organized by folders. In addition to these models, you also have Sources. Let's look at each one:
- Sources: Represent the raw tables ingested from any data source you have.
- Staging: The first abstraction from the source that cleans up and transforms the data into the most basic or universal form usable downstream. Business logic isn't at this layer; it should only clean up the source data, such as renaming columns for fixing data types.
- Intermediate: Provide additional transformations for more complex end Tables and Views. Here, you can introduce some business logic.
- Marts: Marts are the final end-consumer Tables and Views, ultimately what is seen by the users of this data. There should always be at least one staging model between the source and mart. Additionally, marts are typically not referenced into another Mart, helping avoid breaking changes.
Staging Models
When we break our models apart, we have SQL building blocks that can be put together to accomplish different tasks. It might be a common transformation of data you reuse often, or it can also be multiple tables that are joined together in a final Mart.
Let's take a look at the code to create a staging table. When examining the dbt code, you will notice that a best practice is to utilize CTEs or Common Table Expressions. Check out the following article for more information: 1 Trick That Changed the Way I Write Queries Forever.
You might also notice that we don't have the normal create or replace view code wrapped around here. That particular operation is taken care of automatically by dbt based on your project settings, determining whether they materialize as a View or a Table.
with source as (
select *
from
),
renamed as (
select
to_number(deal_id) as deal_id,
to_number(company_id) as company_id,
to_number(type_id) as type_id,
_fivetran_synced as freshness_date
from source
)
select * from renamed
You might also notice that there is a special way to reference the source tables. The code, , will later compile to the proper table name based on your configuration. The renamed CTE can be used to alias any columns or fix data types.
Marts
The next step of the process is to create the end-user-facing Marts. The process is very similar; instead of referencing the source tables, we reference the staging tables with the following code: . The rest of the process is similar to writing any query. Here, I'm taking information from various tables to make a user-friendly presentation of sales in process or complete, otherwise known as Deals.
with deals as (
select
deal_id,
property_days_to_close as days_to_close,
property_closedate as close_date,
property_hs_tcv as total_contract_value,
property_dealname as deal_name,
deal_pipeline_stage_id as stage_id,
property_amount as final_deal_value,
property_hs_is_closed as is_closed,
property_hs_date_entered_closedwon as date_closed_won
from
where is_deleted = false
),
deal_company as (
select distinct
deal_id,
company_id
from
),
company as (
select
id,
property_name as customer
from
),
deal_stages as (
select
stage_id,
label as deal_stage
from
)
select
d.deal_id,
c.customer,
d.deal_name,
d.is_closed,
ds.deal_stage,
d.date_closed_won,
d.days_to_close,
d.total_contract_value,
d.final_deal_value
from deals d
join deal_company dc on d.deal_id = dc.deal_id
join company c on c.id = dc.company_id
join deal_stages ds on ds.stage_id = d.stage_id
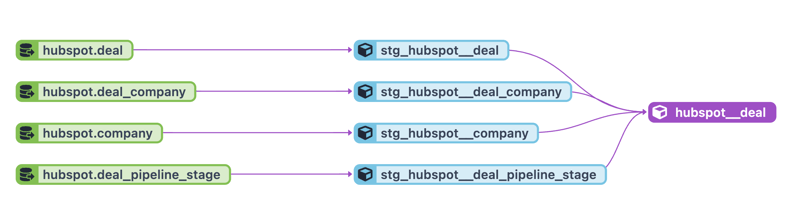
dbt does a fantastic job of rendering a Lineage graph of your models. These visuals are enormously helpful in understanding your project and troubleshooting errors. In this example, the sources are in green, the staging tables are in blue, and finally, our mart is in purple. There is also a common naming convention for each level of your project, which is also depicted below.
Automated Testing
One very helpful feature of dbt is the ability to Test the output of your tables as you build them.
An example I've run into where dbt saved me happened when I made a small change to a query, which caused a duplicate row for every record. Most Marts have a single row per unique identifier. Because I had a unique test on the primary key column, dbt caught the error and prevented my change from being put into production.
There are two primary methods of adding tests:
- General Tests: Tests are built into the solution to check for common problems. These tests run every time the solution is built. The tests are
not_null,unique,accepted_values, andrelationships, allowing you to check those conditions with a single configuration line within your project. - Singular Tests: Singular tests are
.sqlfiles that, if they return results, will cause a failure. Any query you can write that will return failing records. Singular tests allow you endless possibilities to add robustness to your code.
The following is what the code looks like to add tests on a column of our Deals Mart.
version: 2
models:
- name: hubspot__deal
columns:
- name: deal_id
tests:
- unique
- not_null
Deployments
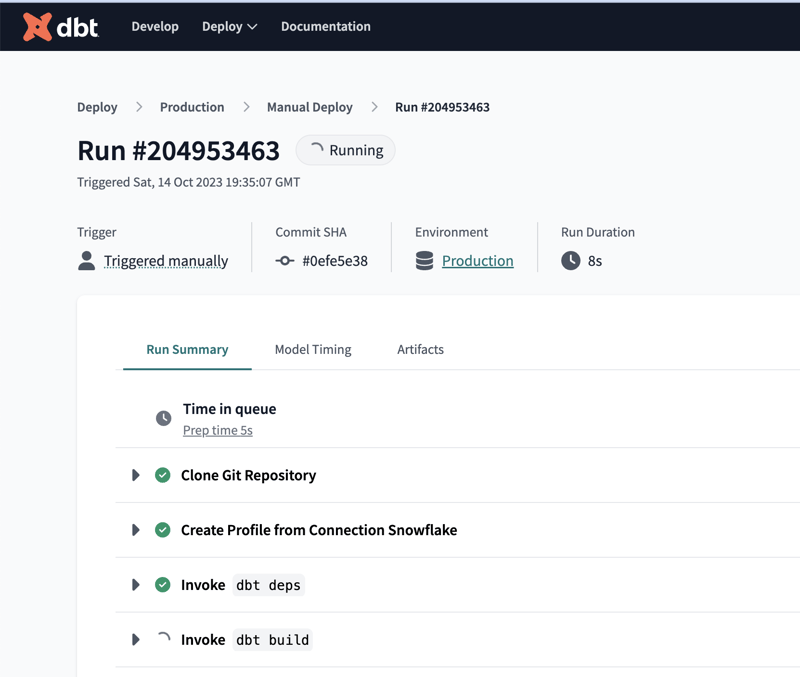
Finally, it's time to get our models deployed into production. dbt Cloud has built-in mechanisms with options such as manual deployments, running on a schedule, and running on Pull Requests (from Git-based solutions). You can even create multiple jobs as they're referred to, to capture multiple use cases.
While I touched on dbt in this article, I highly suggest you dig in for yourself with in-depth, hands-on training provided by dbt. Visit dbt Learn and check out the course dbt Fundamentals. They have several other courses as well which will get you well on your way to being a dbt practitioner.
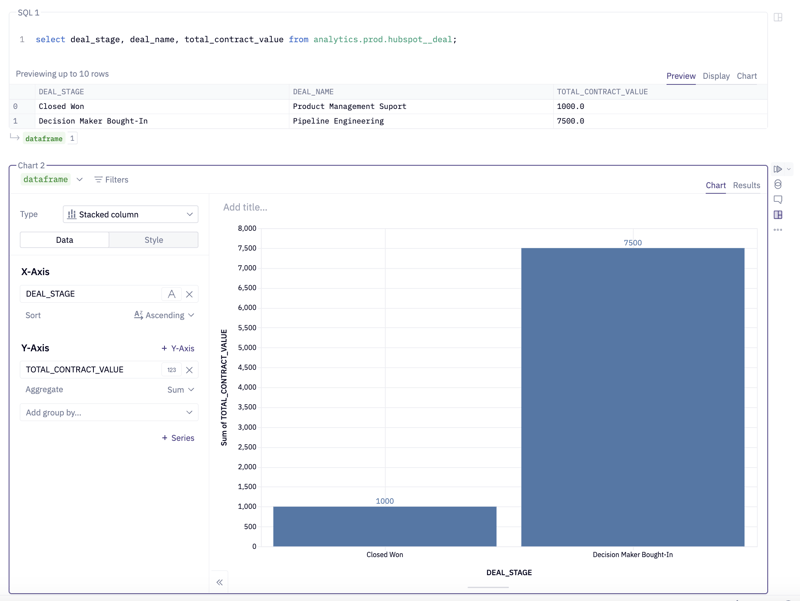
Results
Now that our data is deployed, we can leverage it in a Business Intelligence tool of choice!
Conclusion
Traditionally, we loaded data into a data warehouse through Extract, Transform, and Load or ETL. Modern Data Warehouses invert the second and third parts of the process to perform what is known as ELT. There comes some complexity when managing your code for transforming your data; enter dbt. I covered the concept of a Model in dbt and the process of breaking your original code into more reusable, modular parts. I then discussed tests in dbt, which help protect you from inadvertent errors in your SQL code. Finally, I deployed the model into production and surfaced it in a Business Intelligence tool for consumption. I hope this interests you in learning more. dbt is a fundamental tool for Data Analysts, Data Scientists, and Data Engineers.