By
By
What is AWS EMR
AWS EMR is Amazon's implementation of the Hadoop Distributed Computing Platform, designed to handle Big Data. EMR stands for Elastic MapReduce, and elastic is often used to describe how AWS scales resources. MapReduce refers to the programming model for distributed computing from Google's original implementation. MapReduce has since been generalized and is widely used.
There are numerous use cases for AWS EMR such as:
- Run large scale data processins jobs
- Build scalable data pipelines
- Process real-time data streams
- Accelerate data science and ML adoption
However, you probably want to learn this technology without a massive headache if you're like me.
What is Big Data?
Big Data does not have a definitive definition but can refer to so large and complex that it cannot be processed on a single machine, such as a personal computer or a virtual machine. One of the most important criteria for big data is that it adheres to the 3 V’s - Variety, Velocity, and Volume.
- Variety refers to different types of data, structured, semi-structured, and unstructured data.
- Velocity is how fast is all of the data coming - either batch or streaming. Batch takes a group of data, typically grouped by time, and sends that group simultaneously to the big data system. Streaming data is where data sources constantly write data to the big data platform, and streaming data is typically only scanned once.
- Volume is the amount of data processed in amounts such as petabytes, exabytes, or zettabytes.
Two other V’s are also sometimes considered, value, or how much insight is derived from it, and veracity, or the truthfulness/quality of the data.
What are the Advantages of EMR?
If you've ever tried to install Hadoop or parts of the Hadoop ecosystem such as Apache Spark, you will find that it's a non-trivial task. Additionally, if you're running it on a Mac or Windows, you will probably run into hurdles and compatibility issues instead of Linux. For example, I use an M1 Macbook and could not get it run due to compatibility issues even with choosing a prebuilt Docker Image.
WARNING: The requested image's platform (Linux/amd64) does not match the detected host platform (Linux/arm64/v8) and no specific platform was requested.
Additionally, if you get things installed locally, you may run into other compatibility issues such as Java Runtime Environment conflicts.
The solution? AWS! With a few clicks, you can have a fully provisioned EMR cluster running for you to perform your analysis.
Basic Steps
- Create a non-root IAM account for use with this process
- Create a cluster with all components needed to run Notebooks and Spark
- Create a new Notebook attached to the Cluster
- Run analysis
- Stop the Notebook and terminate the Cluster
- Continue your analysis
Step 1: Creating a Non-Root IAM User
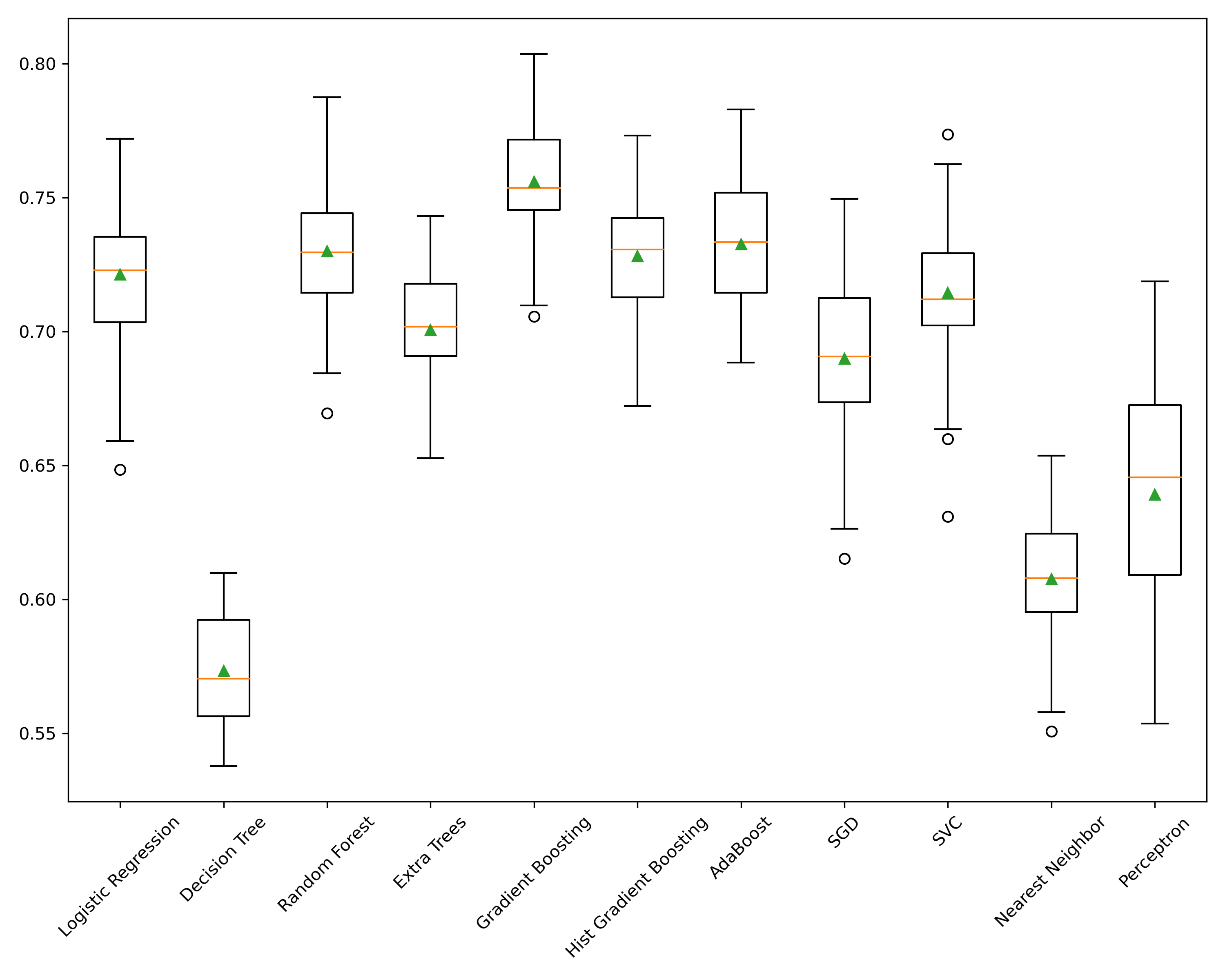
It's important not to use the root account for this process. In most cases, the Notebook environment will fail to start/attach to the Python or PySpark kernels after initializing. To overcome this, create the account with the appropriate permissions. I used the following as a generic catch-all; I didn't try to get to the bare minimum.
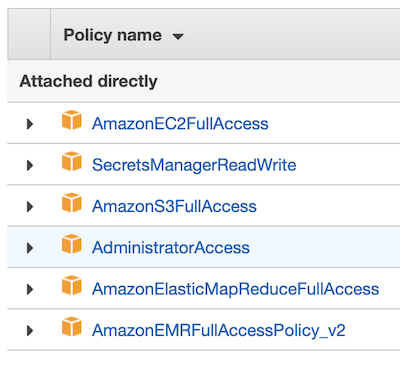
Step 2: Create a New Cluster
Next, you want to create a new cluster. The image below shows all relevant settings you can access through the Advanced Configuration Options. You can add others as well, but these are the items—specifically the two Jupyter entries and Livy, a restful service for Spark.
Step through to the final page and make sure you select a PEM file that you will associate with the cluster. It will be important to access Hadoop, Hue, Spark, and User Interfaces.
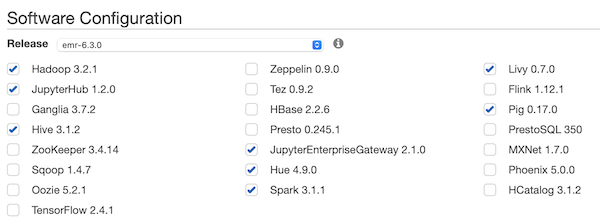
Step 3: Create a New Notebook
Next, Create Notebook in EMR. While you can create a cluster for yourself, it's important to select the one you just created. Use the Choose existing cluster option. This process will allow you to kill the cluster, and in turn, re-create it without losing data and the ability to continue coding on your cluster/Notebook.
Step 4: Analyze Your Data
When programming against Apache Spark in Python you will use the library pyspark. Here is a tiny example of what MapReduce looks like in Python:
# Import and create an instance of SparkContext
from pyspark import SparkContext
sc = SparkContext()
# Create a small list of data in the SparkContext
B=sc.parallelize(range(4))
B.collect()
Out [1]: [0, 1, 2, 3]
# Run a simple MapReduce Routine
B.map(lambda x:x*x).reduce(lambda x,y:x+y)
Out [2]: 14
Your analysis can take many forms on Spark. Check out the PySpark Documentation to get started.
Step 5: After Analysis - Terminating
You can easily build up a very large bill with EMR and clusters. You must stop the Notebook and Terminate the cluster.
- First,
stopthe Notebook but do not delete it. - Second,
terminatethe cluster. It's impossible to stop them, but you can recreate them later.
Step 6: Continuing Your Analysis
When you're ready to continue with your analysis, simply Clone the cluster and wait for it to start. Then return to the Notebook from earlier, and then use the Change Clusterbutton at the top to associate it with your newly cloned cluster.
Conclusion
Spark is a powerful computing environment that can be a critical skill to learn. Deploying it locally, however, can be a difficult task that could consume hours of your time. By utilizing AWS EMR, you can deploy Spark in a matter of minutes and be productive immediately. However, keep in mind that running these resources can be costly, and therefore follow the steps above to shut down and terminate the cluster when you're done. Happy computing!